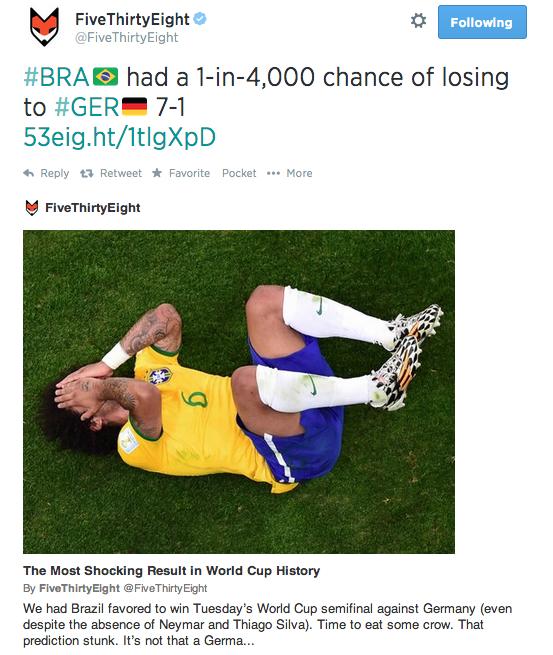
[vc_row][vc_column width=”1/1″][vc_column_text]Germany defeated Brazil in the World Cup semi-finals. It was a brutal 7-1 drubbing and was totally unexpected! So, how does this relate to data?
Many of us who work with data hail all possibilities (see the Age of the Algorithm). But the two above sentences point to the two most common pitfalls I see when I work with business partners.
Do not trust it too much – Data may fail us
Based on data, there are many systems predicting soccer results. Take the ESPN’s Soccer Power Index (SPI). It scores the defensive or offensive power of each player based on historic goal differences and sums it up for each team constellation. The Elo Rating system uses historical match data, but weights it according to the importance of the match. And Transfermarkt relies on the actual monetary value of each player.

(seen on Facebook)
However, none of those systems would have ever predicted a 1:7 defeat of Brazil. Nate Silver, the mastermind behind ESPN’s score, tweeted that the likelihood of this outcome was 1 in 4000.
What did we learn from this? Data can fail us! (Tweet this) Yes, no one wants to hear this story in the midst of big data hype – but we are often faced with questions where there is not enough data to give a good prediction. No matter whether the prediction is one in 400 or one in 4000, anyone would have said that 7 goals were highly unlikely. But “highly unlikely” does not mean impossible. We need to understand when working with data that models have their restrictions. Predictions are probabilities and they are not absolute truths. Not yet convinced? The world is full of ‘unlikely to happen’ events. In soccer, you only need to look at Czechoslovakia beating Argentina in the 1958 World Cup with a very unlikely 6 to 1 final score (see a short video here). We need to understand when working with data that models have their restrictions. Predictions are probabilities and they do not tell the absolute truth, and can only give an indication. Business leaders who understand that predictions are just probabilities will have so-called business discontinuity planning for the very unlikely (but still probable) case of all facilities being lost in a fire … or an employee’s terrible decision that costs the firm dearly … or an unexpected uprising in a country where a majority of products are produced … or (you fill in the blank).
Learn about the shortcomings
Yes, we all love data and it does not always have to be big data, as I pointed out in this blog post. Data will help us to predict, but we need to learn to use it correctly by not underestimating the unlikely probabilities. If you want to learn more about how to work with data, check out my book “Ask Measure Learn” from O’Reilly Media.[/vc_column_text][/vc_column][/vc_row]